





Abstract
Genetic recombination is a very important evolutionary mechanism that mixes parental haplotypes and produces new raw material for organismal evolution. As a result, information on recombination rates is critical for biological research. In this paper, we introduce a new extremely fast open-source software package (FastEPRR) that uses machine learning to estimate recombination rate (=) from intraspecific DNA polymorphism data. When and the number of sampled diploid individuals is large enough (), the variance of remains slightly smaller than that of . The new estimate (calculated by averaging and ) has the smallest variance of all cases. When estimating , the finite-site model was employed to analyze cases with a high rate of recurrent mutations, and an additional method is proposed to consider the effect of variable recombination rates within windows. Simulations encompassing a wide range of parameters demonstrate that different evolutionary factors, such as demography and selection, may not increase the false positive rate of recombination hotspots. Overall, accuracy of FastEPRR is similar to the well-known method, LDhat, but requires far less computation time. Genetic maps for each human population (YRI, CEU, and CHB) extracted from the 1000 Genomes OMNI data set were obtained in less than 3 d using just a single CPU core. The Pearson Pairwise correlation coefficient between the and maps is very high, ranging between 0.929 and 0.987 at a 5-Mb scale. Considering that sample sizes for these kinds of data are increasing dramatically with advances in next-generation sequencing technologies, FastEPRR (freely available at http://www.picb.ac.cn/evolgen/) is expected to become a widely used tool for establishing genetic maps and studying recombination hotspots in the population genomic era.
Genetic recombination exchanges genetic material, produces new haplotypes during meiosis, and plays a critical role in organismal evolution (Coop and Przeworski 2007). In living organisms, this process is highly regulated, and, because its rate varies along the genome, much attention has been paid to identifying recombination hotspots (Baudat et al. 2010). Increased knowledge about recombination will be useful for studies of linkage disequilibrium (LD) (Auton et al. 2013; Hill and Robertson 1968; Ohta and Kimura 1971), admixture (Price et al. 2009; Pugach et al. 2011), natural selection (Hernandez et al. 2011; Sattath et al. 2011), and associated work on genetic diseases (Weiss and Clark 2002).
Recombination rates can be estimated by experimentally counting the number of such events during meiosis (Hudson and Kaplan 1985; Myers and Griffiths 2003). However, the application of this approach is limited because of the extremely low frequency of recombination. This issue can be overcome on the one hand by sequencing a large number of parent-offspring pairs (Kong et al. 2010) using a large amount of sperm from a single male (Lu et al. 2012). On the other, the number of recombination events that occurred in the past can be inferred via coalescent theory and population genetics; in this approach, population recombination rate is denoted as , where is the effective population size, and the recombination rate per generation. Over the last two decades, a number of methods that use likelihood models to estimate recombination rates from intraspecific DNA polymorphism data have been proposed. Of these, full-likelihood methods, including importance sampling (Griffiths and Marjoram 1996; Fearnhead and Donnelly 2001), Markov Chain Monte Carlo (MCMC) (Kuhner et al. 2000), and Bayesian MCMC (Nielsen 2000; Wang and Rannala 2008, 2009) have proved the most accurate for estimating . However, because full-likelihood approaches are very computationally expensive, even with moderately-sized data sets, a composite-likelihood method based on two-locus sampling probabilities was also proposed to estimate (Hudson 2001). Under the infinite-site model, this method calculates the probabilities of all pairs of segregating sites, and then multiplies all these pairwise probabilities to calculate a composite likelihood. Fearnhead and Donnelly (2002) then proposed that the region of interest should be divided into subregions, with the likelihood of each subregion combined as a composite likelihood. Others have argued that, because the infinite-site model is often violated, two-locus sampling probabilities can instead be obtained using Monte Carlo simulations in a finite-site mutation model (McVean et al. 2002). This improved approach is implemented in the LDhat software package (http://ldhat.sourceforge.net/) with, most recently, a varying recombination rate model applied to calculate a composite likelihood (Auton and McVean 2007). Li and Stephens (2003) have also developed “product of approximate conditionals” (PAC) method, which calculates an approximation for conditional likelihood. In sum, although these composite-likelihood methods are relatively simpler computationally than full-likelihood approaches, calculations are still time-consuming.
In our recent work, building on the infinite-site model, we proposed a -estimator using boosting, a machine learning method (Lin et al. 2013). In this context, boosting is used to select the best regression model between recombination rate and a number of summary statistics. Estimates for using our new method are as precise as others, but it is biased in some circumstances. Thus it may limit the application of the machine learning method. In this paper, we extend the machine learning method and present a very fast software package (FastEPRR) to estimate population recombination rate using intraspecific DNA polymorphism data. First, because it has been suggested that it is important to consider the finite-site model when estimating the recombination rate (McVean et al. 2002), our implementations take into account violations of the infinite-site model (i.e., multiple hits). Second, we introduce a linear correction and demonstrate that estimates using FastEPRR are unbiased. Third, we propose a method (Supplemental Material, Figure S1) to take into account the effects of variable recombination rates within windows. Finally, as a test case, we analyze the 1000 Genomes phased OMNI data set (Altshuler et al. 2012) to calculate local recombination rates for three major human populations with African (YRI), European (CEU), and East Asian (CHB) ancestry. The Pearson correlation coefficient between estimates made using either FastEPRR or LDhat is very high, and ranges between 0.929 and 0.987 at a 5-Mb scale. Notably, to estimate the genome-wide recombination rates for one population, FastEPRR only needs less than 3 d based on a single CPU core of a computer. Indeed, when a computer cluster was used, the analysis was completed in just a few hours; therefore, use of FastEPRR dramatically reduces the time required to estimate genome-wide recombination rates, and is just as precise as the well-known method, LDhat.
Materials and Methods
Summary statistics
Demography and selection affect the mutation frequency spectrum (Figure S2), especially the frequency of singletons (Fu and Li 1993). However, we would not suggest simulating data conditional to the mutation frequency spectrum since the importance sampling is relatively time consuming. Instead, we use the compact folded mutation frequency spectrum, named by Li and Stephan (2005), to partially quantify the effects of demography and selection. Indeed, this approach might improve the accuracy of estimates under certain conditions. Suppose that the number of chromosomes in a sample is , and is the number of derived mutations that occur on chromosomes; in this case, the compact folded mutation frequency spectrum is denoted , where , , and . Because the number of folded singletons () will impart little information about recombination, these can be excluded for analysis. The folded singletons are the derived mutations that occur on one and chromosomes.
Let denote the four summary statistics; the mean value of (Hudson 1987) and (Hudson 1985) for all SNP pairs, haplotype heterozygosity, and the number of different haplotypes (). We implemented these four summary statistics in FastEPRR because they contain considerable information about recombination (Wall 2000; Li and Stephens 2003; Kong et al. 2008; Lin et al. 2013), and excluded the folded singletons to calculate .
Regression and linear correction
To obtain the regression model of population recombination rate and the summary statistics conditional on and , we first generated a training set using 0, 0.5, 1, 2, 5, 10, 20, 40, 70, 110, and 170. This training set was simulated using our modified Hudson’s ms simulator (Hudson 2002), conditional on , and (and the pattern of missing data, if necessary), with 100 replicates. Then we used the gamboost (Hothorn et al. 2015) to fit the training set and to establish the regression model . Given the observed four summary statistics (), recombination rate was estimated to be .
We next performed a linear correction to obtain an unbiased estimate by generating 100 simulated data sets given and estimated for each. In this case, we use as the mean value for estimated in the simulated data sets, and . Thus, estimated recombination rate is following linear correction.
It is worth noting that gamboost could produce biased estimates if the real falls out of the range of the training (Lin et al. 2013). More accurately, the observed number of different haplotypes () should fall within the range of in the training set. If we let be the 95th percentile for given , if , and extend the range of the training (i.e., 0, 0.5, 1, 2, 5, 10, 20, 40, 70, 110, 170, 180, 190, 200, 220, 250, 300, and 350) a new regression model can be obtained and the recombination rate re-estimated.
Variable recombination rates within windows
When estimating recombination rate for a given window, we assume that this is constant. However, because this may not be correct, the effect of a variable recombination rate within a given window can be investigated by sliding others over it. For example, if we consider four overlapping sliding windows (i.e., win1, win2, win3, and win4) each with a step length half their size (Figure S1), we can denote , , and as the estimated recombination rate, respectively. If , , and are the real recombination rates of these windows, then we have , , , where denotes the recombination rate for the i-th region. To estimate , , , and , three constraint conditions can be introduced in order:
.
Minimize .
Maximize .
Note that, conditional on , , and , using this procedure , , , and can be estimated, and that conditional on , , and , , , and can be re-estimated. Thus, the estimated is the mean value of all predicted values for .
Validating FastEPRR using simulated data
To validate the performance of FastEPRR, we compared it to our earlier regression-based method (gam), as well as to the composite-likelihood method (implemented in LDhat). Estimates from these three methods are denoted , , and , respectively. In order to estimate , we used a nonparametric model (i.e., a generalized additive model) based on for training (20, 60, 100, 140, and 180) following Lin et al. (2013).
To estimate , we first used the complete program to calculate the likelihoods of all two-locus haplotype configurations, with a population mutation rate and the maximum . Second, we used the pairwise program to estimate the recombination rate.
We studied cases with different sample sizes (i.e., 50, 100, and 200), where is the number of chromosomes but did not include larger sample sizes because LDhat computing time increases dramatically in these cases. Results were not achieved even when we ran LDhat on a state-of-the-art computer cluster with more than 1000 computing nodes.
We simulated neutral data using the coalescent simulator Hudson’s ms, while the data set considered with the hitchhiking model (i.e., positive selection) was simulated using msms (Ewing and Hermisson 2010). To assess the impact of missing data, we treated ms output as a two-dimensional array (i.e., sampled chromosomes as rows and polymorphic sites as columns), and randomly selected cells and marked them as question marks (to denote missing data). In this part of the study, we examined cases of 1, 5, 20, and 30.
To investigate potential bias due to the phasing process, we randomly paired simulated haplotypes to form genotypes (i.e., haplotypes to genotypes). These haplotypes were then reinferred using PHASE v2.1.1 (Stephens et al. 2001; Stephens and Scheet 2005) based on their genotypes and recombination rate estimated from inferred haplotypes.
Application of FastEPRR
To test the application of FastEPRR, we used it to analyze the 1000 Genomes phased OMNI data set (Altshuler et al. 2012). We selected three major human populations for this analysis: 88 individuals from Yoruba in Ibadan, Nigeria (YRI); 85 Utah resident individuals with northern and western European ancestry (CEU); and 97 Han Chinese individuals from Beijing, China (CHB). To estimate local recombination rates on the 22 autosomes, we first scanned each chromosome with nonoverlapping 50 kb sliding windows. For this step, and , the four summary statistics, and the start and end positions of the windows were stored in order as files. Indels and polymorphic sites were excluded from the analysis if their quality score was less than 20, and windows were excluded if they overlapped with known gaps in the reference genome sequence, or if their number of segregating sites () was less than 10. Next, we obtained regression models for each unique combination of and , and then applied these to estimate recombination rates in windows that had the same combination of and for all autosomes. Finally, we merged the recombination rates for all windows to calculate a rate for each autosome, and repeated the analysis for the YRI, CEU, and CHB data sets.
In order to convert estimated into , we first estimated by comparing the total length of the map with overlapping sections of the 2010 deCODE family-based map (Kong et al. 2010). This map provides per generation recombination rates at a 10-kb scale. To obtain pairwise Pearson correlation coefficients for the map, the map (Altshuler et al. 2012), and the 2010 deCODE map for different populations, the three were compared to one another at 50-kb and 5-Mb scales.
To consider the effects of variable recombination rates within windows, we scanned each autosome with overlapping sliding windows (i.e., window size, 50 kb and step length, 25 kb). Following the method described above (Figure S1), we then obtained a genetic map at the 25-kb scale, finer than that at the 50-kb scale.
Implementation
FastEPRR is an R package (open source) that can run across a range of platforms once a standard environment has been installed. This software can be downloaded from our institutional website (http://www.picb.ac.cn/evolgen/softwares/) along with the related genetic maps.
Data availability
The authors state that all data necessary for confirming the conclusions presented in the article are represented fully within the article.
Results
It has been shown that is biased when sample size is small (Lin et al. 2013). We examined the accuracy of by comparing it to and with a fixed number of segregating sites. Results show that is an improvement on , and remains unbiased in the cases we examined (Figure 1), as a linear correction is implemented by FastEPRR. When sample size is small (), has the same level of accuracy as in mean, standard deviation, and the root mean square error (RMSE), while produces estimates with fairly small SD but a certain bias (Figure 1, A–C). When sample size is larger (), the accuracy level of the three methods is almost the same (Figure 1, E–G, and I–K). When it is very large (), FastEPRR still performs well. Indeed, in these cases, the SD of is smaller than that seen in small sample size examples (Figure 1, A, E, and I, and Figure S3). We further investigated this issue and observed that the RMSE of gradually decreases as sample size increases (Table S1), which suggests that the accuracy of is improved at larger sample sizes.
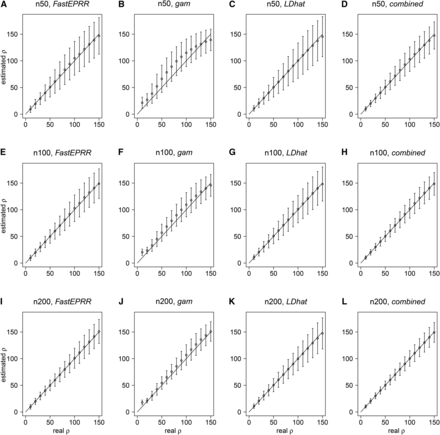
Comparison of , , , and . We compared (A), (E), and (I) with (B), (F), and (J), (C), (G), and (K), and (D), (H), and (L), with the sample sizes of (A)–(D), (E)–(H) and (I)–(L). The number of segregating sites (when ), (when ), and (when ). The mean and the SD of were estimated using simulated data conditional on and , unless noted otherwise.
We then examined the correlation between and in our three simulated cases (Figure 1), and show that the Pearson correlation coefficient is 0.717 (), 0.804 (), and 0.852 (), respectively. The Pearson correlation coefficient is less than 1 because and are based on different recombination signatures. Thus, to improve the accuracy of the estimated recombination rate, we propose a new estimate that combines and together. In this estimate, we denote ; because both and are unbiased, will be also unbiased (Figure 1, D, H, and L). Indeed, in this case, the SD and RMSE of are smallest (Table S2), indicating that is the most accurate way to estimate recombination rate. Similarly, when is fixed, has the same accuracy as (), and the SD of is smallest (Table 1).
Comparison of , and when () is fixed
| Real | FastEPRR | LDhat | Combined | Real | FastEPRR | LDhat | Combined |
|---|---|---|---|---|---|---|---|
| 10 | 9.4 (5.2) | 10.8 (4.3) | 10.1 (3.9) | 90 | 91.5 (23.0) | 91.4 (24.1) | 91.4 (19.9) |
| 20 | 19.8 (6.9) | 20.7 (7.5) | 20.2 (6.0) | 100 | 102.5 (25.0) | 101.4 (26.3) | 101.9 (21.7) |
| 30 | 29.8 (8.7) | 31 (10.1) | 30.4 (7.9) | 110 | 113.3 (26.6) | 111.9 (28.0) | 112.6 (23.0) |
| 40 | 39.4 (10.7) | 40.7 (12.5) | 40.0 (9.9) | 120 | 123.1 (27.1) | 121.3 (29.8) | 122.2 (24.1) |
| 50 | 49.6 (12.8) | 50.9 (15.1) | 50.2 (11.8) | 130 | 132.4 (27.8) | 131.0 (31.0) | 131.7 (24.9) |
| 60 | 60.0 (15.3) | 61.0 (17.3) | 60.5 (13.8) | 140 | 140.8 (28.0) | 139.6 (31.9) | 140.2 (25.2) |
| 80 | 81.5 (20.8) | 81.7 (22.0) | 81.6 (18.2) | 150 | 148.7 (28.3) | 148.4 (31.7) | 148.5 (25.4) |
| Real | FastEPRR | LDhat | Combined | Real | FastEPRR | LDhat | Combined |
|---|---|---|---|---|---|---|---|
| 10 | 9.4 (5.2) | 10.8 (4.3) | 10.1 (3.9) | 90 | 91.5 (23.0) | 91.4 (24.1) | 91.4 (19.9) |
| 20 | 19.8 (6.9) | 20.7 (7.5) | 20.2 (6.0) | 100 | 102.5 (25.0) | 101.4 (26.3) | 101.9 (21.7) |
| 30 | 29.8 (8.7) | 31 (10.1) | 30.4 (7.9) | 110 | 113.3 (26.6) | 111.9 (28.0) | 112.6 (23.0) |
| 40 | 39.4 (10.7) | 40.7 (12.5) | 40.0 (9.9) | 120 | 123.1 (27.1) | 121.3 (29.8) | 122.2 (24.1) |
| 50 | 49.6 (12.8) | 50.9 (15.1) | 50.2 (11.8) | 130 | 132.4 (27.8) | 131.0 (31.0) | 131.7 (24.9) |
| 60 | 60.0 (15.3) | 61.0 (17.3) | 60.5 (13.8) | 140 | 140.8 (28.0) | 139.6 (31.9) | 140.2 (25.2) |
| 80 | 81.5 (20.8) | 81.7 (22.0) | 81.6 (18.2) | 150 | 148.7 (28.3) | 148.4 (31.7) | 148.5 (25.4) |
and . SD of shown in brackets.
| Real | FastEPRR | LDhat | Combined | Real | FastEPRR | LDhat | Combined |
|---|---|---|---|---|---|---|---|
| 10 | 9.4 (5.2) | 10.8 (4.3) | 10.1 (3.9) | 90 | 91.5 (23.0) | 91.4 (24.1) | 91.4 (19.9) |
| 20 | 19.8 (6.9) | 20.7 (7.5) | 20.2 (6.0) | 100 | 102.5 (25.0) | 101.4 (26.3) | 101.9 (21.7) |
| 30 | 29.8 (8.7) | 31 (10.1) | 30.4 (7.9) | 110 | 113.3 (26.6) | 111.9 (28.0) | 112.6 (23.0) |
| 40 | 39.4 (10.7) | 40.7 (12.5) | 40.0 (9.9) | 120 | 123.1 (27.1) | 121.3 (29.8) | 122.2 (24.1) |
| 50 | 49.6 (12.8) | 50.9 (15.1) | 50.2 (11.8) | 130 | 132.4 (27.8) | 131.0 (31.0) | 131.7 (24.9) |
| 60 | 60.0 (15.3) | 61.0 (17.3) | 60.5 (13.8) | 140 | 140.8 (28.0) | 139.6 (31.9) | 140.2 (25.2) |
| 80 | 81.5 (20.8) | 81.7 (22.0) | 81.6 (18.2) | 150 | 148.7 (28.3) | 148.4 (31.7) | 148.5 (25.4) |
| Real | FastEPRR | LDhat | Combined | Real | FastEPRR | LDhat | Combined |
|---|---|---|---|---|---|---|---|
| 10 | 9.4 (5.2) | 10.8 (4.3) | 10.1 (3.9) | 90 | 91.5 (23.0) | 91.4 (24.1) | 91.4 (19.9) |
| 20 | 19.8 (6.9) | 20.7 (7.5) | 20.2 (6.0) | 100 | 102.5 (25.0) | 101.4 (26.3) | 101.9 (21.7) |
| 30 | 29.8 (8.7) | 31 (10.1) | 30.4 (7.9) | 110 | 113.3 (26.6) | 111.9 (28.0) | 112.6 (23.0) |
| 40 | 39.4 (10.7) | 40.7 (12.5) | 40.0 (9.9) | 120 | 123.1 (27.1) | 121.3 (29.8) | 122.2 (24.1) |
| 50 | 49.6 (12.8) | 50.9 (15.1) | 50.2 (11.8) | 130 | 132.4 (27.8) | 131.0 (31.0) | 131.7 (24.9) |
| 60 | 60.0 (15.3) | 61.0 (17.3) | 60.5 (13.8) | 140 | 140.8 (28.0) | 139.6 (31.9) | 140.2 (25.2) |
| 80 | 81.5 (20.8) | 81.7 (22.0) | 81.6 (18.2) | 150 | 148.7 (28.3) | 148.4 (31.7) | 148.5 (25.4) |
and . SD of shown in brackets.
Because the rate of multiple hits is high in many viruses and bacteria (McVean et al. 2002), we examined the sensitivity of to multiple hits under the finite-site model, and found that remains unbiased (Figure 2). In the same way that LDhat considers only sites with two alleles, FastEPRR examines sites where two or more alleles are segregated.
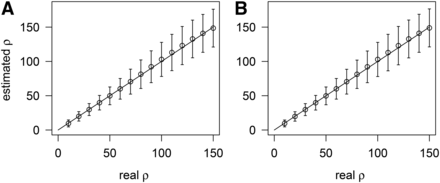
Comparison of with (A), and without (B), multiple hits when . When 52 mutations occur randomly on a 150 bp fragment (A), the probability of multiple hits is 0.99, but when 52 mutations occur randomly on a 10,000 bp fragment (B), this probability decreases to 0.12.
We also considered cases with missing data because it is often expected in sets of genome-wide DNA polymorphisms, especially when sequencing coverage is low. As FastEPRR relies on machine learning, a training set can be generated that has the same pattern of missing data as the input, and can be estimated. When we did this, we found that the SD of increases slightly as the percentage of missing data rises (Figure 3). Nevertheless, still provides a precise and unbiased estimate even when the percentage of missing data are very high (30%).
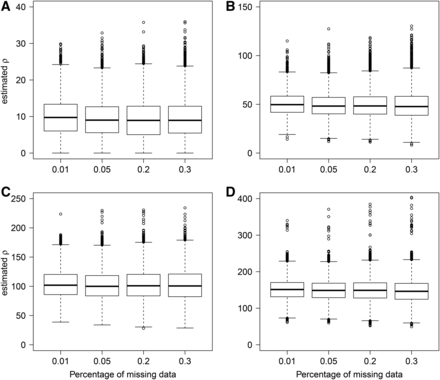
Comparisons of including missing data when The real 10 (A), 50 (B), 100 (C), and 150 (D).
Because FastEPRR requires haplotype information, phased intraspecific DNA polymorphism data has to be used to estimate recombination rate. To study the effect of phasing uncertainty, we compared (estimated from phased haplotypes) and (estimated from real haplotypes). We found that remained unbiased in all the cases we examined (Table 2) and, as expected, the SD of is slightly larger than that of when the recombination rate is large ().
Comparing the performance of FastEPRR when information on real haplotypes is available (), and when the inferred haplotypes are used ()
| Real | Real | ||||
|---|---|---|---|---|---|
| 10 | 9.6 (5.0) | 9.7 (5.0) | 90 | 91.7 (22.3) | 90.1 (22.3) |
| 20 | 19.6 (6.8) | 19.5 (6.8) | 100 | 102.7 (24.8) | 101.0 (24.9) |
| 30 | 29.7 (8.5) | 29.6 (8.5) | 110 | 112.3 (25.9) | 110.7 (26.6) |
| 40 | 39.5 (10.6) | 39.1 (10.4) | 120 | 123.2 (27.5) | 121.6 (28.8) |
| 50 | 49.8 (12.6) | 49.2 (12.5) | 130 | 132.5 (28.1) | 131.2 (29.7) |
| 60 | 60.0 (15.0) | 59.0 (14.7) | 140 | 141.0 (28.9) | 140.4 (32.0) |
| 80 | 81.3 (20.2) | 79.9 (20.0) | 150 | 149.6 (30.0) | 150.1 (34.1) |
| Real | Real | ||||
|---|---|---|---|---|---|
| 10 | 9.6 (5.0) | 9.7 (5.0) | 90 | 91.7 (22.3) | 90.1 (22.3) |
| 20 | 19.6 (6.8) | 19.5 (6.8) | 100 | 102.7 (24.8) | 101.0 (24.9) |
| 30 | 29.7 (8.5) | 29.6 (8.5) | 110 | 112.3 (25.9) | 110.7 (26.6) |
| 40 | 39.5 (10.6) | 39.1 (10.4) | 120 | 123.2 (27.5) | 121.6 (28.8) |
| 50 | 49.8 (12.6) | 49.2 (12.5) | 130 | 132.5 (28.1) | 131.2 (29.7) |
| 60 | 60.0 (15.0) | 59.0 (14.7) | 140 | 141.0 (28.9) | 140.4 (32.0) |
| 80 | 81.3 (20.2) | 79.9 (20.0) | 150 | 149.6 (30.0) | 150.1 (34.1) |
and . The total simulated data sets are conditional on and as used in Figure 1. SD of given in brackets.
| Real | Real | ||||
|---|---|---|---|---|---|
| 10 | 9.6 (5.0) | 9.7 (5.0) | 90 | 91.7 (22.3) | 90.1 (22.3) |
| 20 | 19.6 (6.8) | 19.5 (6.8) | 100 | 102.7 (24.8) | 101.0 (24.9) |
| 30 | 29.7 (8.5) | 29.6 (8.5) | 110 | 112.3 (25.9) | 110.7 (26.6) |
| 40 | 39.5 (10.6) | 39.1 (10.4) | 120 | 123.2 (27.5) | 121.6 (28.8) |
| 50 | 49.8 (12.6) | 49.2 (12.5) | 130 | 132.5 (28.1) | 131.2 (29.7) |
| 60 | 60.0 (15.0) | 59.0 (14.7) | 140 | 141.0 (28.9) | 140.4 (32.0) |
| 80 | 81.3 (20.2) | 79.9 (20.0) | 150 | 149.6 (30.0) | 150.1 (34.1) |
| Real | Real | ||||
|---|---|---|---|---|---|
| 10 | 9.6 (5.0) | 9.7 (5.0) | 90 | 91.7 (22.3) | 90.1 (22.3) |
| 20 | 19.6 (6.8) | 19.5 (6.8) | 100 | 102.7 (24.8) | 101.0 (24.9) |
| 30 | 29.7 (8.5) | 29.6 (8.5) | 110 | 112.3 (25.9) | 110.7 (26.6) |
| 40 | 39.5 (10.6) | 39.1 (10.4) | 120 | 123.2 (27.5) | 121.6 (28.8) |
| 50 | 49.8 (12.6) | 49.2 (12.5) | 130 | 132.5 (28.1) | 131.2 (29.7) |
| 60 | 60.0 (15.0) | 59.0 (14.7) | 140 | 141.0 (28.9) | 140.4 (32.0) |
| 80 | 81.3 (20.2) | 79.9 (20.0) | 150 | 149.6 (30.0) | 150.1 (34.1) |
and . The total simulated data sets are conditional on and as used in Figure 1. SD of given in brackets.
As neutral demographic scenarios (Johnston and Cutler 2012; Kamm et al. 2015) and positive selection (Reed and Tishkoff 2006) may cause the false recognition of recombination hotspots, we investigated the performance of FastEPRR in such cases. For example, when a population bottleneck occurs, both genetic variation and population size are substantially reduced; thus, estimated is reduced (Figure 4, A and B, and Figure S4) compared to the current population recombination rate (, where is the current effective population size), and the variance of is generally smaller than (Figure 4, A and B). Similarly, estimated is also reduced in exponential population growth scenarios compared to a current population recombination rate (Figure 4, C and D). Importantly, its variance remains similar with that calculated under the standard neutral model (Figure 1E); therefore, recombination hotspots revealed by FastEPRR might not be due to the confounding effect of demography. Indeed, as FastEPRR is based on coalescent simulations, it would be possible to infer when demography parameters are estimated (Gutenkunst et al. 2009; Li and Stephan 2006; Li and Durbin 2011), but this is beyond the scope of this study. Positive selection reduces the DNA polymorphism level at linked neutral loci via the hitchhiking effect so a reduced is expected (Figure 5) when compared to a population recombination rate estimated with the standard neutral model. Thus, positive selection cannot explain the recombination hotspots revealed by FastEPRR.
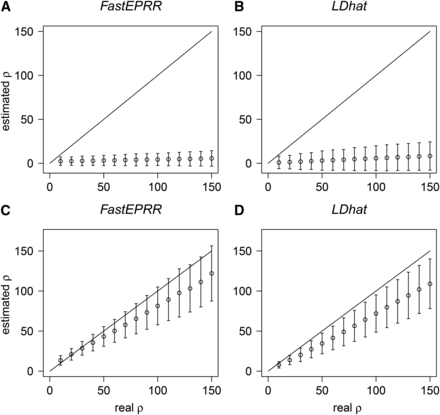
Comparisons of (A) and (C), and (B) and (D) under population bottleneck (A) and (B) and population exponential growth (C) and (D) conditions. , and the time is scaled so that one unit represents generations. For population bottleneck, we assume that duration , and that the time of bottleneck ended , and , where is the effective population size before, and after, the bottleneck, and is the effective population size during the bottleneck. For population exponential growth, expansion time , and , where and are the current and ancestral effective population sizes, respectively.
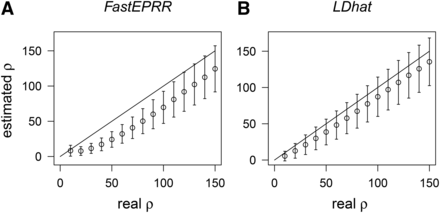
Comparison of (A) and (B) under the hitchhiking model. ,, , and the time after the beneficial allele gets to fixation (in units of generations), where is the effective population size, the selection coefficient.
Our analysis of the 1000 Genomes OMNI data set (Altshuler et al. 2012) to estimate genome-wide (chr1-chr22) in three human populations (i.e., African, YRI, European, CEU, and East Asian, CHB, ancestry, see above) shows that the average per megabase in each case is 939.66 (YRI), 474.31 (CEU), and 544.75 (CHB). Using the 2010 deCODE family-based genetic map, average for each population is thus 1.1703 cM/Mb (YRI), 1.1702 cM/Mb (CEU), and 1.1704 cM/Mb (CHB). Using estimates for of 20,073 (YRI), 10,133 (CEU) and 11,636 (CHB), the population recombination rate can be converted as the recombination rate . As an example, we show recombination rates () for chromosome 7 at the 50-kb scale for the YRI, CEU, and CHB populations (Figure 6), while recombination rates for the 22 autosomes are given in Figure S5. Recombination rates show a large degree of along-chromosome variation in the YRI population (Figure 7A), an overall trend that persists in all three populations (Figure 6). In the YRI population, the vast majority of recombination events occur in a small fraction of the sequence, i.e., 70% of recombination events occur in 30% of the sequence (Figure 7B). On the other hand, recombination activity in the CEU and CHB populations is more concentrated (Figure S6), in agreement with previous findings (Altshuler et al. 2010).
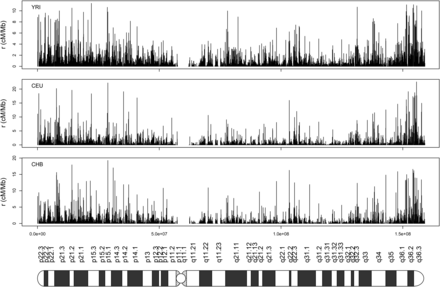
Recombination rates of chromosome 7 for three human populations of African (YRI), European (CEU), and East Asian (CHB) ancestry at a 50-kb scale. The cartoon at the bottom is a visualization of the chromosome.
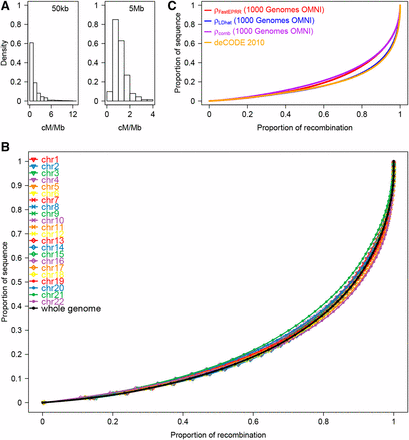
Recombination rate in the African population (YRI). (A) Histograms of the recombination rate for the whole autosomal genome at 50-kb and 5-Mb scales, respectively. (B) Proportion of recombination in different fractions of the sequence. Each colored line represents one chromosome, while the black line denotes the whole autosomal genome. (C) Concentration of recombination in a small proportion for the four genetic maps.
We compared the map with the one from based on both the same data (Altshuler et al. 2012), and the 2010 deCODE family-based map (Kong et al. 2010). Overall, the map is slightly more concentrated than the other two (Figure 7C and Figure S6), which means that is more conservative in detecting recombination hotspots. We also calculated pairwise Pearson correlation coefficients for the three genetic maps of the three populations at 50-kb and 5-Mb scales (Table 3 and Figure S7); comparing the and maps, these coefficients range between 0.729 and 0.903 at the 50-kb scale, and between 0.929 and 0.987 at the 5-Mb scale. Thus, the two maps are highly correlated with one another, and also have a similar correlation coefficient to the 2010 deCODE map. Indeed, the correlation between estimates using FastEPRR and LDhat could be improved further if we consider the effect of variable recombination rates within windows using FastEPRR. Taking this into account, the Pearson correlation coefficients of the and maps for the YRI, CEU, and CHB populations at a 50-kb scale are 0.909, 0.813, and 0.770, respectively.
Pairwise Pearson correlation coefficients among three genetic maps for three human populations
| FastEPRR.YRI | FastEPRR.CEU | FastEPRR.CHB | LDhat.YRI | LDhat.CEU | LDhat.CHB | deCODE | |
|---|---|---|---|---|---|---|---|
| FastEPRR.YRI | 1 | 0.969 | 0.955 | 0.987 | 0.964 | 0.964 | 0.859 |
| FastEPRR.CEU | 0.808 | 1 | 0.965 | 0.957 | 0.956 | 0.951 | 0.847 |
| FastEPRR.CHB | 0.793 | 0.845 | 1 | 0.939 | 0.929 | 0.939 | 0.840 |
| LDhat.YRI | 0.903 | 0.774 | 0.751 | 1 | 0.974 | 0.974 | 0.870 |
| LDhat.CEU | 0.791 | 0.803 | 0.729 | 0.826 | 1 | 0.974 | 0.866 |
| LDhat.CHB | 0.794 | 0.762 | 0.754 | 0.830 | 0.852 | 1 | 0.876 |
| deCODE | 0.626 | 0.601 | 0.554 | 0.641 | 0.679 | 0.655 | 1 |
| FastEPRR.YRI | FastEPRR.CEU | FastEPRR.CHB | LDhat.YRI | LDhat.CEU | LDhat.CHB | deCODE | |
|---|---|---|---|---|---|---|---|
| FastEPRR.YRI | 1 | 0.969 | 0.955 | 0.987 | 0.964 | 0.964 | 0.859 |
| FastEPRR.CEU | 0.808 | 1 | 0.965 | 0.957 | 0.956 | 0.951 | 0.847 |
| FastEPRR.CHB | 0.793 | 0.845 | 1 | 0.939 | 0.929 | 0.939 | 0.840 |
| LDhat.YRI | 0.903 | 0.774 | 0.751 | 1 | 0.974 | 0.974 | 0.870 |
| LDhat.CEU | 0.791 | 0.803 | 0.729 | 0.826 | 1 | 0.974 | 0.866 |
| LDhat.CHB | 0.794 | 0.762 | 0.754 | 0.830 | 0.852 | 1 | 0.876 |
| deCODE | 0.626 | 0.601 | 0.554 | 0.641 | 0.679 | 0.655 | 1 |
Pairwise Pearson correlation coefficients among three genetic maps for three populations (YRI, CEU, and CHB) at a 50-kb scale are shown in the lower left triangle, while those at a 5-Mb scale are in the upper right triangle. FastEPRR.YRI, FastEPRR.CEU and FastEPRR.CHB denote the maps for the three populations, LDhat.YRI, LDhat.CEU, and LDhat.CHB denote the maps, and deCODE denotes the 2010 deCODE family-based map.
| FastEPRR.YRI | FastEPRR.CEU | FastEPRR.CHB | LDhat.YRI | LDhat.CEU | LDhat.CHB | deCODE | |
|---|---|---|---|---|---|---|---|
| FastEPRR.YRI | 1 | 0.969 | 0.955 | 0.987 | 0.964 | 0.964 | 0.859 |
| FastEPRR.CEU | 0.808 | 1 | 0.965 | 0.957 | 0.956 | 0.951 | 0.847 |
| FastEPRR.CHB | 0.793 | 0.845 | 1 | 0.939 | 0.929 | 0.939 | 0.840 |
| LDhat.YRI | 0.903 | 0.774 | 0.751 | 1 | 0.974 | 0.974 | 0.870 |
| LDhat.CEU | 0.791 | 0.803 | 0.729 | 0.826 | 1 | 0.974 | 0.866 |
| LDhat.CHB | 0.794 | 0.762 | 0.754 | 0.830 | 0.852 | 1 | 0.876 |
| deCODE | 0.626 | 0.601 | 0.554 | 0.641 | 0.679 | 0.655 | 1 |
| FastEPRR.YRI | FastEPRR.CEU | FastEPRR.CHB | LDhat.YRI | LDhat.CEU | LDhat.CHB | deCODE | |
|---|---|---|---|---|---|---|---|
| FastEPRR.YRI | 1 | 0.969 | 0.955 | 0.987 | 0.964 | 0.964 | 0.859 |
| FastEPRR.CEU | 0.808 | 1 | 0.965 | 0.957 | 0.956 | 0.951 | 0.847 |
| FastEPRR.CHB | 0.793 | 0.845 | 1 | 0.939 | 0.929 | 0.939 | 0.840 |
| LDhat.YRI | 0.903 | 0.774 | 0.751 | 1 | 0.974 | 0.974 | 0.870 |
| LDhat.CEU | 0.791 | 0.803 | 0.729 | 0.826 | 1 | 0.974 | 0.866 |
| LDhat.CHB | 0.794 | 0.762 | 0.754 | 0.830 | 0.852 | 1 | 0.876 |
| deCODE | 0.626 | 0.601 | 0.554 | 0.641 | 0.679 | 0.655 | 1 |
Pairwise Pearson correlation coefficients among three genetic maps for three populations (YRI, CEU, and CHB) at a 50-kb scale are shown in the lower left triangle, while those at a 5-Mb scale are in the upper right triangle. FastEPRR.YRI, FastEPRR.CEU and FastEPRR.CHB denote the maps for the three populations, LDhat.YRI, LDhat.CEU, and LDhat.CHB denote the maps, and deCODE denotes the 2010 deCODE family-based map.
We also established another genetic map using (by averaging and ) (Figure 7C and Figure S6) as this provides the most accurate estimate for recombination rate. In this case, the Pearson correlation coefficients between the map and the 2010 deCODE map are 0.867 (YRI), 0.865 (CEU), and 0.869 (CHB) at a 5-Mb scale.
Complete genome-wide analysis of each population took less than 3 d on a single computer with a normal AMD Opteron(tm) 800 MHz processor using a single core (Table S3). Computing time for the genome-wide analysis of the YRI, CEU, and CHB populations (using a sliding window length of 50 kb) was 66.3, 45.7, and 49.0 hr, respectively. Indeed, if a small computer cluster (i.e., 12 CPUs with four cores per CPU) was used, each analysis could be completed within less than 4 hr, and this time could be further decreased if the number of nodes were increased. FastEPRR will thus prove a very useful piece of software for the analysis of genome wide polymorphism data from large samples, for example the UK10K project (Walter et al. 2015) and other projects.
Discussion
In this study, we introduce FastEPRR, a very fast piece of software that estimates population recombination rates from intraspecific DNA polymorphism data. FastEPRR is a much improved extension of our previously proposed regression-based method (Lin et al. 2013) that can be supported by computer clusters and so is suitable for the analysis of population genomic data even when sample sizes are very large. Furthermore, the new software excludes the number of folded singletons () because they have no effect on the number of different haplotypes as recombination rates increase (Figure S8). Our evaluation of the performance of FastEPRR with, and without, (Figure S9), shows almost the same results in terms of means and the SD of estimated recombination rate. In agreement with previous work (Hudson and Kaplan 1985), we show that provides little information about recombination.
We also demonstrate that FastEPRR is naturally robust to multiple hits, one very important feature as it has been argued that these cannot be underestimated when calculating recombination rate (McVean et al. 2002). Moreover, because FastEPRR is a coalescent-simulation-based approach, it can handle the missing data often encountered in genomic scale population data sets. Simulations show that the phasing process does not affect recombination rate estimates when . Indeed, when , estimates are still unbiased, but their variance increases slightly as it may be difficult to infer haplotypes. As a result, a reasonable window size should be used when estimating .
Our simulations show that the FastEPRR software provides the same degree of accuracy as well-known composite-likelihood methods but requires very little computation time. Using a single CPU core, for example, FastEPRR took less than 3 d to analyze the 1000 Genomes OMNI data set (Altshuler et al. 2012), a task that would take LDhat years. The Pearson correlation coefficient between the and maps is between 0.929 and 0.987 at a 5-Mb scale.
We propose that has the smallest variance, when compared with and . Because is the average of and , computation time for will be determined mainly by . Thus, can be used when sample sizes are small, and it is not difficult to estimate in such cases. However, we recommend using at larger sample sizes.
Sample sizes are expected to increase dramatically as sequencing technologies advance and more and more organisms are investigated (Cao et al. 2011; Altshuler et al. 2012; Walter et al. 2015). Whole genomes, or exomes, of nearly 10,000 individuals are included in the UK10K project (Walter et al. 2015), and the rapid construction of genetic maps is increasingly important to biological research. Next, we plan to apply the FastEPRR software to the UK10K data to establish the genetic map of the 10,000 individuals, a computational analysis we expect to take less than 2 wk. When complete, we will provide this map free on our website (http://www.picb.ac.cn/evolgen/softwares/) to facilitate other studies and to promote FastEPRR as a useful, fast, and effective tool for creating genetic maps and studying recombination hotspots in the genomic era.
Acknowledgments
We thank Richard Durbin and Lisa D. Brooks for providing references and information about OMNI data usage, and Xiaohui Zhao for helpful comments and validation of the FastEPRR program. This work was supported by the Strategic Priority Research Program of the Chinese Academy of Sciences (XDB13040800), the National Natural Science Foundation of China (no. 91531306), and the 973 project (no. 2012CB316505).
Footnotes
Supplemental material is available online at www.g3journal.org/lookup/suppl/doi:10.1534/g3.116.028233/-/DC1
Communicating editor: K. Thornton
Literature Cited
Hothorn, T., P. Buehlmann, T. Kneib, M. Schmid, and B. Hofner, 2015 mboost: model-based boosting. Available at: http://CRAN.R-project.org/package=mboost. Accessed: February 25, 2015.
Kamm, J.A., J.P. Spence, J. Chan, and Y.S. Song, 2015 An exact algorithm and efficient importance sampling for computing two-locus likelihoods under variable population size. arXiv:1510.06017. Available at: http://adsabs.harvard.edu/abs/2015arXiv151006017K. Accessed: October 20, 2015.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}